
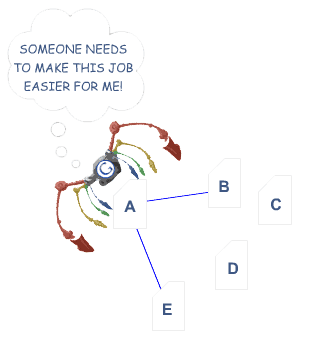
 In the example above, Google's colorful spider has reached page "A" and sees internal links to pages "B" and "E." However important pages C and D might be to the site, the spider has no way to reach them—or even know they exist—because no direct, crawlable links point to those pages. As far as Google is concerned, these pages basically don’t exist–great content, good keyword targeting, and smart marketing don't make any difference at all if the spiders can't reach those pages in the first place.
In the example above, Google's colorful spider has reached page "A" and sees internal links to pages "B" and "E." However important pages C and D might be to the site, the spider has no way to reach them—or even know they exist—because no direct, crawlable links point to those pages. As far as Google is concerned, these pages basically don’t exist–great content, good keyword targeting, and smart marketing don't make any difference at all if the spiders can't reach those pages in the first place.
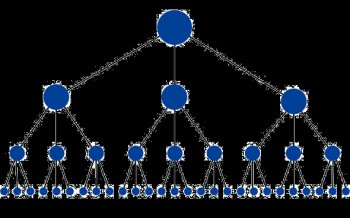
The optimal structure for a website would look similar to a pyramid (where the big dot on the top is homepage):
This structure has the minimum amount of links possible between the homepage and any given page. This is helpful because it allows link juice (ranking power) to flow throughout the entire site, thus increasing the ranking potential for each page. This structure is common on many high-performing websites (like Amazon.com) in the form of category and subcategory systems.
But how is this accomplished? The best way to do this is with internal links and supplementary URL structures. For example, they internally link to a page located at with the anchor text "cats." Below is the format for a correctly formatted internal link. Imagine this link is on the domain jonwye.com.
In the above illustration, the "a" tag indicates the start of a link. Link tags can contain images, text, or other objects, all of which provide a "clickable" area on the page that users can engage to move to another page. This is the original concept of the Internet: "hyperlinks." The link referral location tells the browser—and the search engines—where the link points. In this example, the URL is referenced. Next, the visible portion of the link for visitors, called "anchor text" in the SEO world, describes the page the link is pointing at. In this example, the page pointed to is about custom belts made by a man named Jon Wye, so the link uses the anchor text "Jon Wye's Custom Designed Belts." The tag closes the link, so that elements later on in the page will not have the link attribute applied to them.
This is the most basic format of a link—and it is eminently understandable to the search engines. The search engine spiders know that they should add this link to the engine's link graph of the web, use it to calculate query-independent variables (like MozRank), and follow it to index the contents of the referenced page.
Below are some common reasons why pages might not be reachable, and thus, may not be indexed.
Links in Submission-Required Forms
Forms can include elements as basic as a drop–down menu or elements as complex as a full–blown survey. In either case, search spiders will not attempt to "submit" forms and thus, any content or links that would be accessible via a form are invisible to the engines.
Links Only Accessible Through Internal Search Boxes
Spiders will not attempt to perform searches to find content, and thus, it's estimated that millions of pages are hidden behind completely inaccessible internal search box walls.
 Links in Un-Parseable Javascript
Links in Un-Parseable Javascript
Links built using Javascript may either be uncrawlable or devalued in weight depending on their implementation. For this reason, it is recommended that standard HTML links should be used instead of Javascript based links on any page where search engine referred traffic is important.
Links in Flash, Java, or Other Plug-Ins
Any links embedded inside Flash, Java applets, and other plug-ins are usually inaccessible to search engines.
Links on pages with Hundreds or Thousands of Links
The search engines all have a rough crawl limit of 150 links per page before they may stop spidering additional pages linked to from the original page. This limit is somewhat flexible, and particularly important pages may have upwards of 200 or even 250 links followed, but in general practice, it's wise to limit the number of links on any given page to 150 or risk losing the ability to have additional pages crawled.
Links in Frames or I-Frames
Technically, links in both frames and I-Frames are crawlable, but both present structural issues for the engines in terms of organization and following. Only advanced users with a good technical understanding of how search engines index and follow links in frames should use these elements in combination with internal linking.
By avoiding these pitfalls, a webmaster can have clean, spiderable HTML links that will allow the spiders easy access to their content pages. Links can have additional attributes applied to them, but the engines ignore nearly all of these, with the important exception of the rel="nofollow" tag.
Rel="nofollow" can be used with the following syntax:
In this example, by adding the rel="nofollow" attribute to the link tag, the webmaster is telling the search engines that they do not want this link to be interpreted as a normal, juice passing, "editorial vote." Nofollow came about as a method to help stop automated blog comment, guestbook, and link injection spam, but has morphed over time into a way of telling the engines to discount any link value that would ordinarily be passed. Links tagged with nofollow are interpreted slightly differently by each of the engines.
Related Tools
The MozBar SEO toolbar lets you see relevant metrics in your browser as you surf the web.
Open Site Explorer is a free tool that gives webmasters the ability to analyze up to 10, 000 links to any site or page on the web via the Mozscape web index.
External Resources
The original PageRank algorithm research paper written by Google co-founders Larry Page and Sergey Brin.
Google's Official Guidelines for Webmasters.
Head of the Webspam Team at Google, Matt Cutts', thoughts on hyperlinks in relation to SEO and Google.
Related Guides
Moz's comprehensive guide to the practice of search engine optimization for those unfamiliar with the subject.
RELATED VIDEO



RELATED FACTS
-
 A gas engine is an internal combustion engine which runs on a gas fuel, such as coal gas, producer gas biogas, landfill gas or natural gas. In the UK, the term is unambiguous. In the US, due to the widespread use of "gas" as an abbreviation for gasoline, such an...
A gas engine is an internal combustion engine which runs on a gas fuel, such as coal gas, producer gas biogas, landfill gas or natural gas. In the UK, the term is unambiguous. In the US, due to the widespread use of "gas" as an abbreviation for gasoline, such an...
-
 A turbocharger, or turbo (colloquialism), from the Greek "τύρβη" (mixing/spinning) is a forced induction device used to allow more power to be produced for an engine of a given size. The key difference between a turbocharger and a conventional supercharger is that...
A turbocharger, or turbo (colloquialism), from the Greek "τύρβη" (mixing/spinning) is a forced induction device used to allow more power to be produced for an engine of a given size. The key difference between a turbocharger and a conventional supercharger is that...
Share this Post
latest post
-
 Waste Management Lafayette Indiana November 14, 2023
Waste Management Lafayette Indiana November 14, 2023 -
 New Zealand Waste Management November 10, 2023
New Zealand Waste Management November 10, 2023 -
 Waste Management Spokane Valley Waste November 6, 2023
Waste Management Spokane Valley Waste November 6, 2023 -
 Waste Management Baltimore November 2, 2023
Waste Management Baltimore November 2, 2023 -
 Waste Management Fort Wayne October 29, 2023
Waste Management Fort Wayne October 29, 2023 -
 Industrial Waste Management October 25, 2023
Industrial Waste Management October 25, 2023 -
 Waste Management Macomb IL October 21, 2023
Waste Management Macomb IL October 21, 2023 -
 What is Waste disposal? October 17, 2023
What is Waste disposal? October 17, 2023 -
 Waste Management Pittsburgh PA October 13, 2023
Waste Management Pittsburgh PA October 13, 2023